A Deep Dive into the P2P Layer of the Dencun Hardfork
14 Jun 2024
Authors: Mikel Cortes, Guillaume MichelIntroduction #
The networking layer is the core component of any distributed blockchain or peer-to-peer (p2p) network. It is the base and the channel of any interaction across participating nodes that makes the higher-level application protocols work. Ethereum is no different in this case.
Since its early beginnings in 2015, the Ethereum network has seen multiple upgrades on its multiple components, “The Merge” being perhaps, one of the most significant achievements. The transition process did not only target the update of the consensus to a permission-less PoS, but also meant the aggregation of a totally new parallel networking layer for the Beacon Chain.
Once both chains were “merged” into a single one, the network still relied on two different layers of communication: The Execution Layer (EL) maintains the previously existing set of protocols and handshakes to propagate users’ interaction with the chain, while the Consensus Layer (CL) relies on a new set of networking protocols to propagate validators’ duties that help to achieve consensus:
- Peer discovery over the Discovery 5 Distributed Hash Table (DHT):
discv5 - Host and RPC calls exchanges through
libp2p - Message propagation over libp2p’s
gossipsubprotocol.
All these components primarily ensure that nodes can synchronously make decisions based on consensus. Thus enabling the whole application concept of a blockchain.
Motivation of the studies #
Most of the hard forks apply one or many significant changes in the Ethereum protocol, but it’s not only the protocol itself that is affected by these significant upgrades.
However, hard forks always represent stressing moments for the network (and the community), because:
- Despite the fact that the proposed changes and the fork transitions are always tested in testnets, these networks don’t always have the same conditions as the mainnet chain (node count, sudden spikes of user interactions, etc). Thus, the success of the upgrade is never guaranteed.
- The epoch or slot of the transition means stressing moments for the participant nodes. There are some epochs where the two fork-versions coexist, as there are always nodes that didn’t upgrade their version and end up on forks from the previous
fork_version(they can’t keep up with the new additions) or nodes that simply stayed behind following the chain. - The changes mostly add some degree of workload to the networking protocols. The changes almost always imply modifications or the addition of RPC calls or messages to distribute over the network, which can increase resource utilization (CPU on processing messages, bandwidth on sending them, etc).
The Cancun-Deneb hard fork wasn’t different in that regard. The upgrade implemented the first simple but straightforward “data-sharding” implementation proposed by Proto-Danksharding. This represents the first approach of the network to implement the bigger and more ambitious Danksharding (still WIP).
Proto-Danksharding introduced the concept of blob_transactions on the EL, which comes along with the aggregation of six new gossipsub topics (blob_sidecar subnets) on the CL.
Without removing the importance of all the significant upgrades on the application and consensus layer, the focus of this blog post is to analyze the internals of two of the main P2P components and the effect that the upgrade had on the P2P layer more generally:
- The public DHT of
discv5: With each occurring hard fork or main upgrade in the network since the emergence of the CL, each of the participants needs to update their ENR’sfork-digestaccording to the newestfork_versionof the network they participate in. Thus, a big overview of the DHT could help us understand the dynamics at the P2P networking layer that took place on the Deneb upgrade of the network, and understand how the network organizes around these big events. - The
gossipsubnetworking layer: Due to the proposed target of including threeblob_sidecarson each beacon block, and the significant size that these ones can have, the impact of this addition to the overall performance of thegossipsubprotocol can’t be negligible. Thus, a thorough study of the internal performance of the protocol on thoseblob_sidecarsubnets can provide a bigger picture of the impact that these messages have on the operation of the node.
We believe that both studies can help us understand the current state of the network, showcasing the level of adoption of major updates in the network and the room for improvement that both protocols have.
Studies #
The Deneb upgrade observed from the discv5 DHT
#
The ProbeLab team is producing weekly reports on the discv5 Distributed Hash Table (DHT), focusing particularly on Ethereum mainnet. Our reports offer valuable insights into various aspects of the DHT population, including user agent distributions, cloud usage, and geographic distribution. We are using the Nebula Crawler to enumerate all participants of the discv5 network and gather information for them. You can explore more about our methodology here.
Recently, these reports have provided crucial data regarding the Deneb hardfork migration process. In this post, we will dive into some of the key results and offer explanations for the observed trends. For a detailed overview of the week of the hardfork, including all pre-fork (Capella) and post-fork (Deneb) plots, please visit our complete report.
Nodes changing fork digest #
The network was upgraded on Wednesday 2024-03-13 at 13:55 UTC (source), and we can clearly see it from the data we gathered. Our crawler runs every 30 minutes, and we observed that ~73% of the all nodes that participate to Deneb by the end of the week were already present during the crawl right after the fork happened (crawl of 2024-03-13 14:25). This shows that most peers have upgraded right on time, and it took hours for the ~27% percent to switch from Capella to Deneb.
We can observe that 28% of the nodes associated with the Capella fork digest (0xbba4da96) kept associated with the Capella fork digest after the fork, implying that they didn’t migrate to using the Deneb fork digest (0x6a95a1a9). We will try to explain this using additional plots later on.
From both plots we also observe that by the end of the week, there are more Deneb nodes (~7,800), than nodes that left Capella (~6,700). This implies that ~1,100 new nodes appeared with the fork. Some node operators may have started a new node using Deneb fork digest while keeping the node using the Capella fork digest online for some time.
We note that after 1 week, Deneb has approximately 1400 less nodes (-15%) than Capella had right before the fork.
Client versions #
Unsurprisingly, we can see in the following plot that all nodes who have joined Deneb run Consensus Layer client versions that are compatible with Deneb, and a majority of them is running the recommended version.
The client version distribution is more interesting for Capella nodes. For Lighthouse, teku and lodestar, we see that the number of nodes running a Deneb-compatible version increased up until the fork. This means that node operators have been upgrading their non-Deneb-compatible version, to a newer version supporting the new fork. At the exact time of the fork, almost all Deneb-compatible versions changed their fork digest to the Deneb one. For the rest of the week, the number of nodes remaining in Capella kept decreasing.
The numbers are very different for Prysm nodes. Up to the time of the fork, we observed many node operators upgrading from 4.x to 5.0, which is the only Deneb-compatible Prysm version. However, at the time of the fork, only 50% of Prysm nodes were Deneb-compatible, and only 76% of these nodes disappeared from Capella. This implies that 70% of Prysm nodes remained in Capella after the fork. Prysm made up 36% of the network before the fork, in second place behind Lighthouse (40%).
Roughly 1,000 Prysm nodes left Capella at the time of the fork, and roughly 2,100 Prysm nodes joined Deneb at the same time. This explains the additional 1,100 records mentioned above, they are new Prysm nodes that were launched when the fork happened.
Country distribution #
We observe that the node geographical distribution is almost identical on Capella pre-fork as on Deneb-post fork. No big change here.
It can be noted that the percentage of nodes hosted in Germany is slightly higher in Capella post-fork than in Capella pre-fork or Deneb post-fork.
Cloud hosting #
We immediately notice that the cloud hosting rate wasn’t changed due to the fork. Pre- and post-fork, there are approximately 46% of nodes that are hosted from known data centers.
Stale peer records #
The following plots depict the count of node records stored within each node’s routing table and made accessible through the DHT. These node records serve as mechanism through which nodes discover new remote nodes in the network.
Ensuring the reachability of referenced nodes shared within the network holds paramount importance. The plot delineates the occurrences of reachable and non-reachable (stale) node records. Note that nodes running behind a NAT are counted as unreachable even though they may be online.
For instance, if a node’s record is present in the routing tables of 100 other nodes and the node is reachable, the plot will reflect an increase of 100 in the reachable category.
The first plot displays data about all nodes participating in discv5 regardless of their fork_digest, so they include Capella, Deneb as well as other networks and testnets.
We can see that the overall number of records didn’t change during the fork, nor the overall ratio of reachable vs unreachable peer records. The significant amount of Stale Peer Records remains, but this is subject to a separate study.
We observe that the percentage of unreachable peer records is lower in Deneb (~20%) than in the overall network (~25%). This means that Deneb-compatible clients are certainly better at flushing unreachable peers compared with other clients.
When comparing peer records in Capella (pre-fork) and Deneb, we observe that Deneb has less peer records overall, which is certainly because Deneb counts less peers than pre-fork Capella. We see that the pre-fork unreachable peer records ratio was much higher in Capella (~27%) than it is in Deneb (~20%). This ratio is even higher for Capella pre-fork than the average of all discv5.
We notice that after the fork, the unreachable peer records ratio even goes up to 50%. This can be explained by the fact that the older clients, that may be less efficient at flushing unresponsive peers from their routing table aren’t Deneb-compatible, and hence stayed in Capella with their unreachable peer records.
Hence, from the perspective of network health the Deneb fork allowed the network to get rid of less efficient clients and their unreachable peers records by leaving them behind during the upgrade.
We can note that Ethereum mainnet makes up for approximately half of all peer records in discv5.
Deneb adoption over time #
The numbers discussed so far are limited to the week when the fork happened. We can see on the following plot that the number of beacon nodes participating in Deneb continued to increase. The client with the largest growth from the end of the fork week until 2024-05-12 is Prysm with an increase of 15% (400 new nodes).
We can also see that the number of participants in Capella has steadily decreased since the end of the first week. The largest population of Prysm nodes has fallen from 2,000 nodes on 2024-03-18 down to only 850 by the 2024-05-12, a drop of 57%.
We assume that many Prysm nodes have simply upgraded to Deneb late. However, the number of Prysm nodes that have left Capella is higher than the number of Prysm nodes that have joined Deneb.
The number of node having left Capella and not joined Deneb (1,150 - 400 = 750) is compensating for the 1,100 new nodes have been added around the time of the fork, discussed earlier. It is hard to tell whether the number would match by the time most Prysm nodes have exited Capella, because fresh peers may also join Deneb now.
Our guess on why so many Prysm nodes have remained in Capella is because they weren’t able to upgrade straight away, so they sprung up fresh Prysm 5.0 instances in addition to the older versions that were still running. After a while, the older versions, now useless are being turned off.
GossipSub metrics on blob sidecars topics #
Gossipsub has played a significant role in the development and implementation of the consensus layer. It has been heavily used by all beacon nodes to propagate crucial messages such as bleacon_blocks, attestations, or aggregations, which help secure the chain.
Since Deneb, its purpose has been extended to help propagate blob_sidecars that come along the blob_transactions .
This report aims to measure the performance impact that adding these new message topics has had on each beacon node’s gossipsub service, providing some internal metrics of the protocol that has been measured by our “light-node”, Hermes.
Hermes connects to the Ethereum network, tracing all occurring p2p events at the libp2p host level, allowing us to analyze the internal events of the gossipsub service.
NOTES:
-
Due to the significant size of the raw data to reproduce this study, the study has been limited to a three-hour run of our
Hermesinstance running in Ethereum mainnet between 13/06/2024 at 20:30 pm and 13/06/2024 at 23:45 pm. -
Hermes has a significantly bigger number of simultaneous connections (at the host level, not at the mesh level). However, due to the
GossipFactor, this can alter the number of sent/received messages. We still believe, though, that the results here represent reality accurately in terms of percentages.
Gossip effectiveness for blob_sidecar subnets #
As the Deneb upgrade of the network includes six new subnet topics, there is an expected increase in the number of message IDs shared among each IHAVE message in the network and, in turn, an increase in the number of IWANT messages.
The protocol uses these IHAVE and IWANT messages as an active measurement against shadowing attacks, as nodes can request from non-mesh connected peers any message that they weren’t aware of.
The following paragraphs introduce the effectiveness of those metadata messages in the wild, understanding the effectiveness of the ratio of IWANT messages received per the shared IHAVE message.
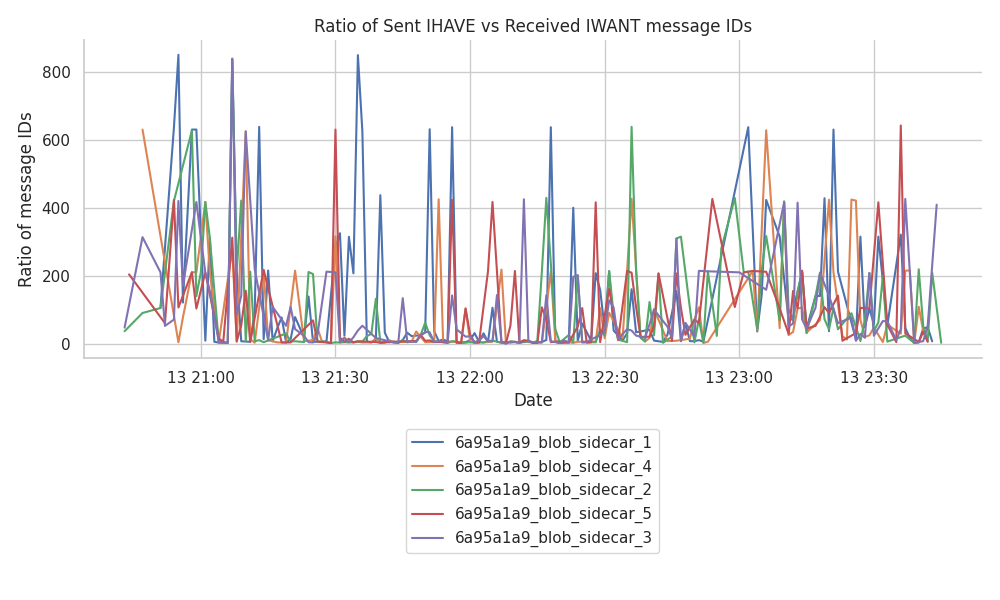
Sent IHAVEs vs received IWANTs
The direct gossip effectiveness can be understood as the ratio of IHAVE message IDs that we are sending for each of the IWANT message requests that we receive back. In this case, the measurement shows how useful a node is for its peer connections (not strictly the direct mesh-connected ones) and how useful those IHAVE messages that we send are.
In the following graphs, we observe that the effectiveness of the blob_sidcar messages is not as steady as we could observe in other measurements for topics like aggregates_and_proofs or sync_committee_contribution_and_proof topics.
In fact, due to its similarity in message frequency (1msg/slot) with the beacon_block topic, we can see that both patterns look quite alike.
![]()
The figure shows that with such a low frequency of messages in comparison to other topics, the ratio (on a minute basis) spikes. We see that in some cases, the ratio can reach ~400:1 or even the ~1000:1 sent IHAVE messages per each IWANT message received.
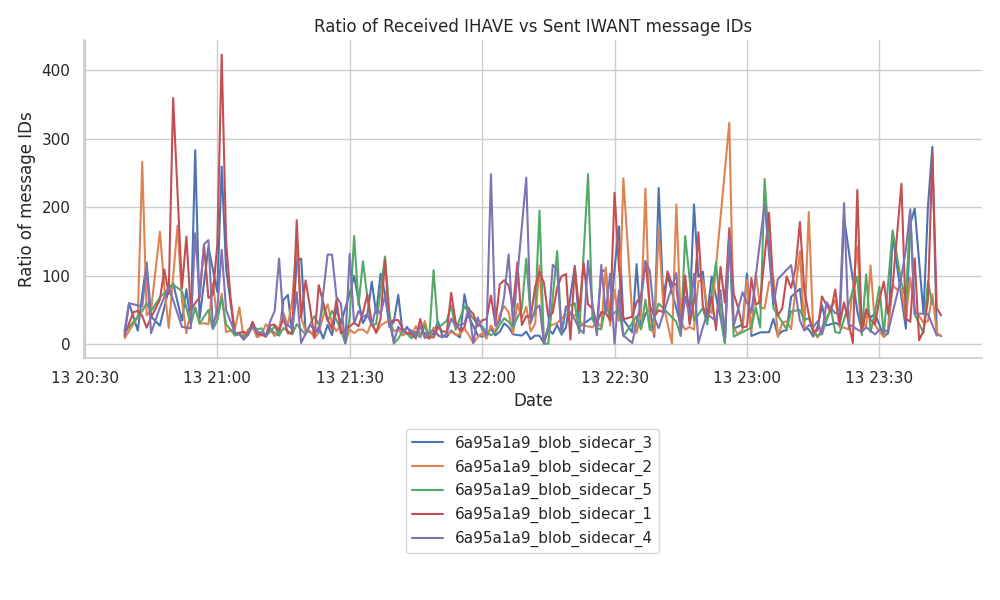
Received IHAVEs vs sent IWANTs
We’ve also contemplated the opposite case, where the effectiveness of the gossip mechanism can also be assessed by the number of IHAVE message IDs that a node receives, versus the messages it requests through IWANT. This is because resources are also used to receive and process incoming messages.
In the following figures, we can see that the ratios are more stable than the previously presented ones. In the graph, we can observe that the ratio oscillates between ~20:1 and ~50:1, sometimes reaching ~100:1, ~200:1, and ~400:1 on some rare occasions.
Message arrivals and duplicates #
Despite gossipsub implementing further optimizations over pubsub to reduce the bandwidth usage for message broadcasting, it is still far from being perfect. It is known that distributed broadcasting messages are prone to generate and receive duplicate messages, and these two approaches also fall into that problem.
With the latest Deneb upgrade and the aggregation of blob_sidecards messages, it is expected to see an increasing trend in network bandwidth usage. However, due to the lack of public data on the internal performance of gossipsub, the impact that this hard fork has on the network’s performance remains unknown.
Blob messages are capped to a maximum size of 128KB each (or 131.072 bytes), but as the current road-map seems to focus on increasing the target blobs per slot, we believe it is important to measure the bandwidth used on messages duplicates to estimate better which is the correct target of blobs that can still be handled at a home staking setup.
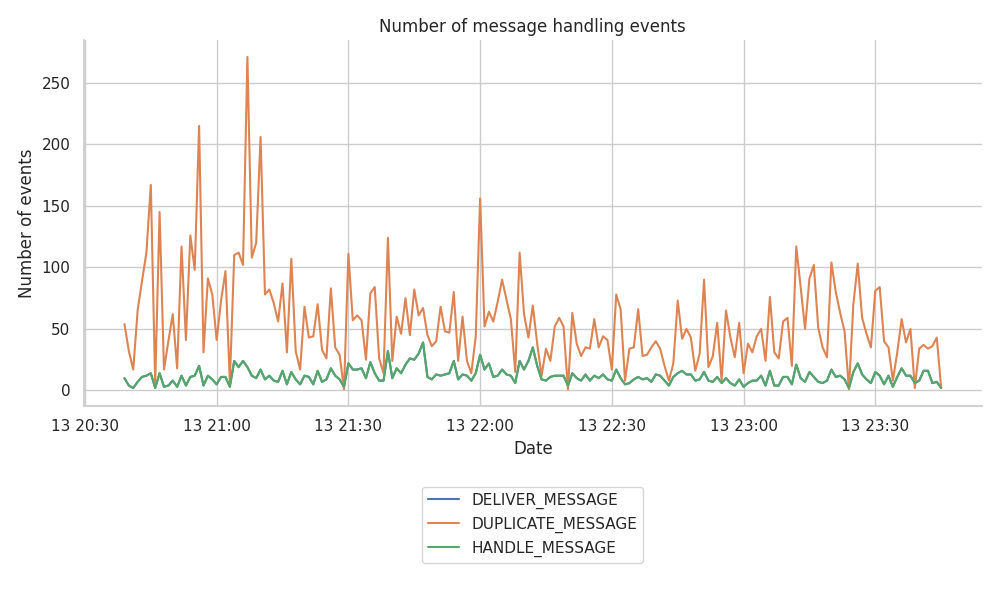
The decided target on the number of blobs per slot at the spec level was three. Over the three hours of the run, Hermes was able to track some degree of oscillation over the targeted mark of 18 blobs/minute, reaching, on some occasions, the upper limit of 36 blobs per minute or 6 blobs per slot. Although it is an unusual case, beacon_block can “safely” reach the limit of blobs expected by the protocol. However, there is no such limit on the number of duplicates that can arrive at each host.
The following figure shows that the Hermes host tracked over 250 duplicated messages in a single minute, peaking an average ratio of ~5 duplicates per message to ~17 duplicates per message.
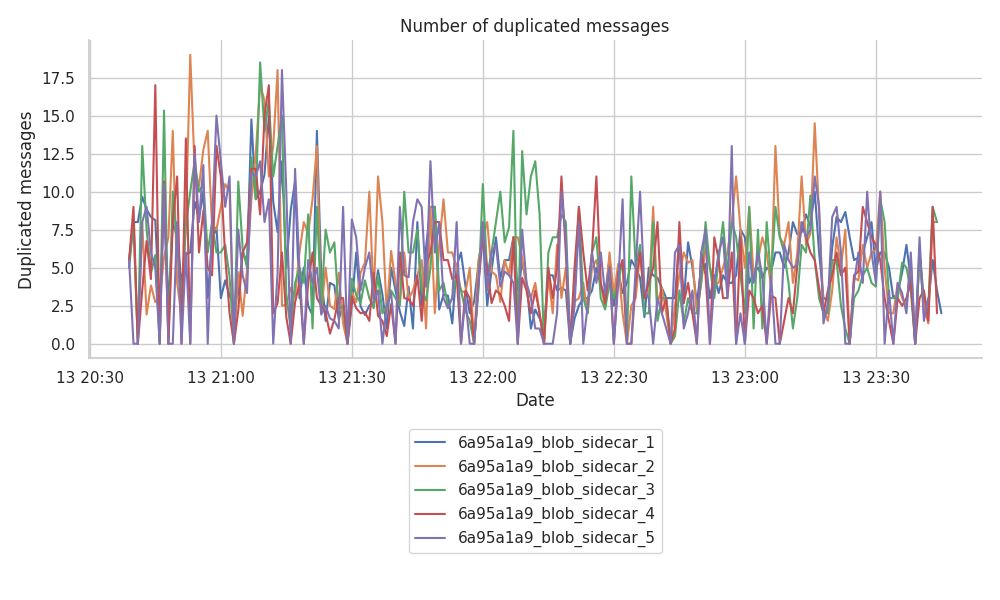
To quantify how big these messages are, as not all the blob_sidecards might be totally full, the following graph shows the CDF of the messages per topic. The figure shows that more than 50% of the “blobs” for all the subnets are full at 128 KB, and only ~20% of the blobs remain below the 48 KB size.
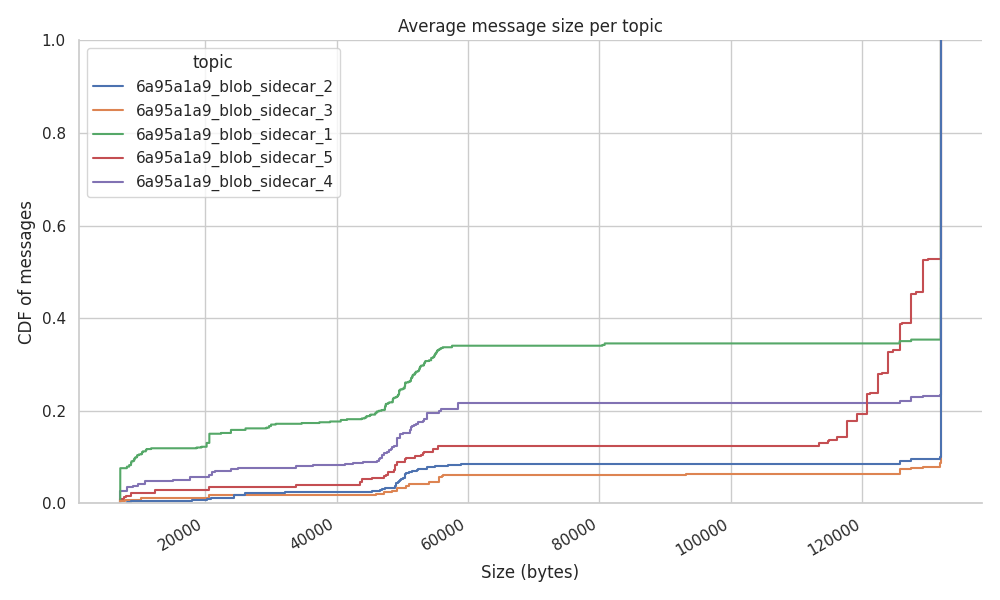
With more than half of the blobs reaching the maximum size and almost matching what is close to the average size of a beacon block, the number of duplicates arriving per message implies a big percentage of the network bandwidth usage.
The following figure shows that around 50% of the messages arrive more than five times, exceeding the 20 duplicate mark in some edgy case exceptions.
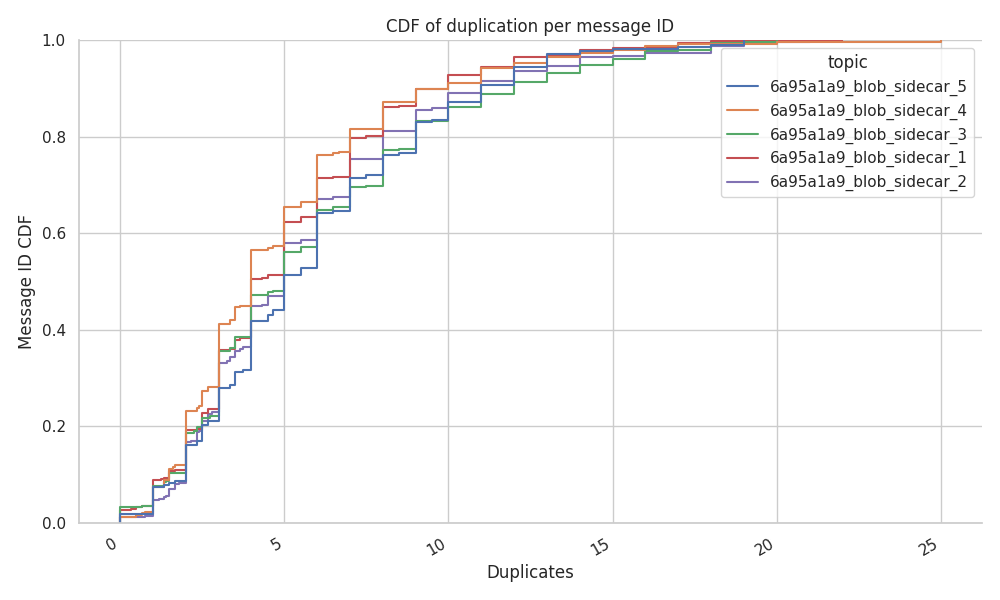
Despite there haven’t been any major reports associated with heavy usage of the network bandwidth after the Deneb hard fork, it is still our duty to showcase that the bandwidth usage can not always be directly linked only to the targeted number of blobs per slot. We’ve identified that there might be sudden spikes in the number of duplicates that could exhaust the bandwidth of some home setups.
Conclusions #
From the discv5 observations, we can conclude by saying that the fork happened smoothly, with Deneb’s population currently being 95% of Capella’s pre-fork population. Many Prysm nodes didn’t operate the fork_digest change in the first hours after the upgrade, but eventually made the transition. It can be noted that the Cloud Hosting Providers and Geolocation distributions remained the same throughout the fork.
On the other hand, from gossipsub observations, we can conclude by saying that we’ve identified similarities between the blob_sidecar topics and the beacon_block one at the gossipsub level. Due to the low frequency of both blob messages, these topics benefit from message propagation through gossip without adding any relevant overhead to the bandwidth used on control messages. However, we could identify that with the current size of blobs, the number of duplicates and its previous increase in frequency, reducing the number of duplicates derived from the gossipsub traffic should become a number one priority to help reduce the used bandwidth and help scaling the number of subnets.
Methodology #
All the raw data used to generate the blog-post was gathered by open-sourced tools maintained by the ProbeLab team.