So, you want to use a DHT? Let us help you configure it correctly.
Introduction
This guide walks you through configuring go-libp2p-kad-dht or rust-libp2p/kad for your deployment. The defaults shipped by both implementations are calibrated for the public Amino DHT (the network that IPFS uses). If your deployment looks different along any meaningful axis, you will need to deviate, and the steps below cover where and by how much.
The libp2p Kademlia DHT is a configurable implementation rather than a fixed protocol. The same codebase serves the public Amino DHT, peer-discovery overlays for blockchain networks, and private deployments under custom protocol prefixes. Most parameters can be tuned across orders of magnitude, and the appropriate value depends on what you are using the DHT for and on the operating conditions you expect.
As a point of reference and in order to motivate the fact that network operators should care about the specific settings, it’s worth highlighting how different operational networks that use the libp2p DHT can be. The Amino DHT (IPFS network) is composed of ~3.5k DHT server nodes with very high churn and more than half a million DHT client nodes. On the other hand, there are many DHT-based blockchain networks with less than 500 DHT server nodes, which present close to zero churn. It should be clear that for such stark differences, it’s difficult (even risky) to have a “one-size-fits-all” configuration. This guide helps you pick the right one.
The guide assumes familiarity with Kademlia at the level of the original paper. It does not argue for or against the DHT as a design choice, and it does not cover record validation semantics, transport-layer concerns, or higher-level content routing protocols built on top of the DHT.
The following section At a Glance” summarises the takeaways for readers who want the answer without the walkthrough. The detailed guide then proceeds as a sequence of four steps: Step 1 settles which subsystems of the implementation are active, Step 2 surveys the deployment dimensions that drive parameter choice, Step 3 matches your case to one of five named profiles, and Step 4 covers the provide optimisations for content-routing workloads. The full parameter reference lives in the sister blog post libp2p Kademlia DHT Configuration Parameters.
At a Glance
The configuration surface has roughly four tiers of impact. Most tuning effort tends to be spent in the wrong tier.
The first tier is correctness gates: Operating Mode, Protocol Identifier, and the IP Diversity Filter. The wrong choice produces a node that looks functional but is silently broken. A client masquerading as a server poisons routing tables. A misconfigured prefix joins the wrong network. The diversity filter must be present on public networks and absent on datacenter networks. We have observed the consequences of a misconfigured protocol identifier when the Avail network merged with the IPFS Amino DHT early 2023.
The second tier is the provide optimisations for content-routing deployments. Reprovide Sweep is effectively mandatory above 10^3 CID$s and $makes large corpora viable. Optimistic Provide addresses first-announcement latency for fresh ingest. The Accelerated DHT Client is the older alternative to the sweep, with bursty resource usage, and is no longer the preferred choice for new deployments. Disabling the provide subsystem altogether on a peer-discovery deployment sits in the same tier because it removes a subsystem rather than tuning it.
The third tier contains the continuous knobs that consistently reward attention. k and α together set the replication-versus-latency trade-off and are the most impactful continuous levers. k, which defines both the default bucket size, but more importantly the number of nodes to store a provider record with during publication, is locked at 20 on the /ipfs prefix, but becomes the largest lever once it can move. α, on the other hand, is the query concurrency that defines the number of concurrent requests for a provider record, during record lookups. Refresh Period sets routing table quality, which compounds into the latency of every subsequent lookup. Record TTL governs network-wide record persistence and dictates the publication interval as roughly TTL/2.
Everything else is marginal in isolation: latency tolerance, admission check concurrency, pending entry timeout, bucket insertion strategy, and the various filter hooks.
If you have limited time, focus on the items above and you will already be half-way there. In order to uncover the impact of changing the query concurrency α, we carried out an experiment where we performed lookups for varying α values. The target is to showcase the latency impact that the concurrency factor is having on the retrieval process. The following graph shows the results and corresponding trade-off.
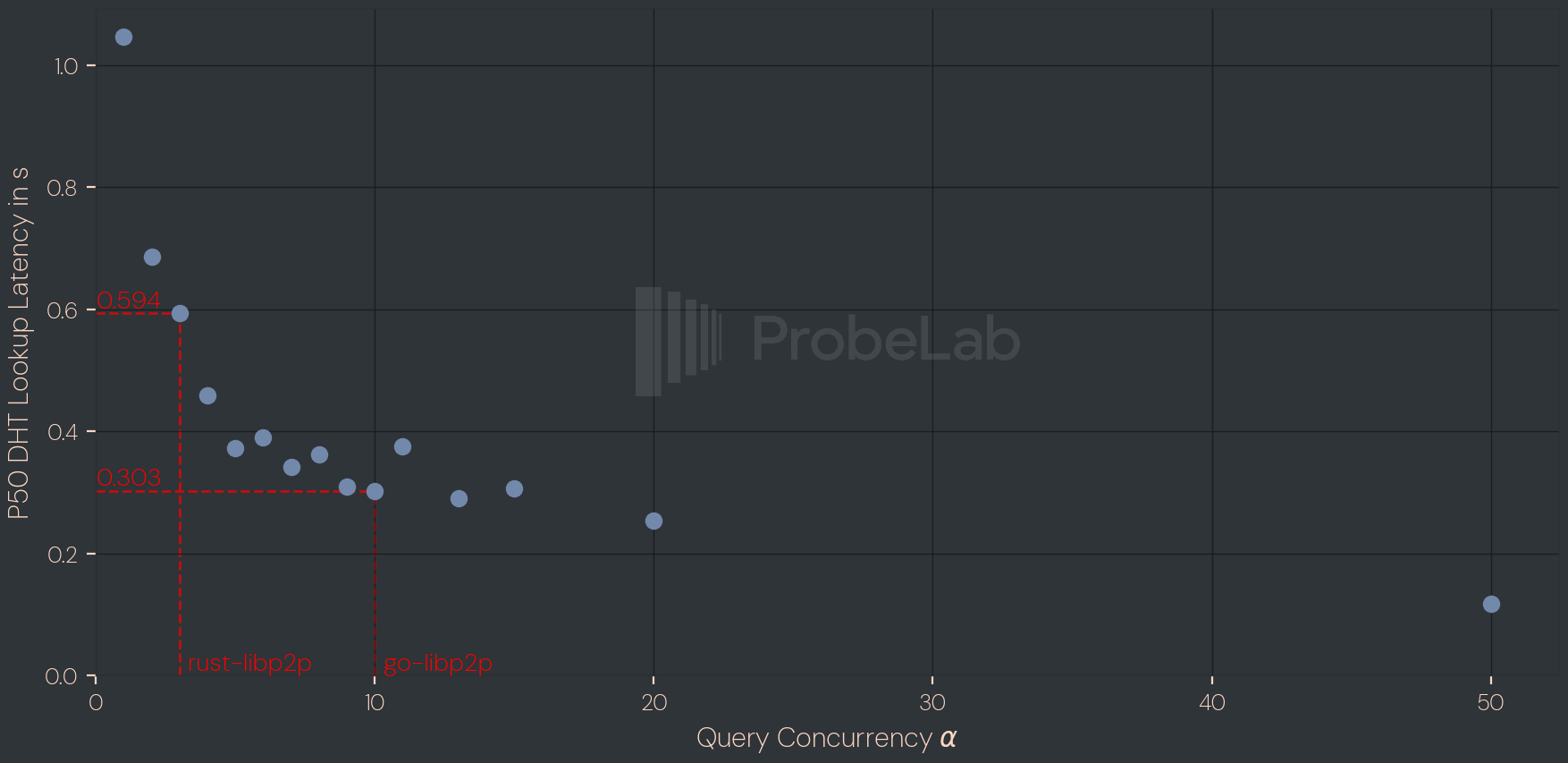
On the public Amino DHT, P50 lookup latency falls from above one second at α=1 to roughly 300 ms by α=10, with sharply diminishing returns past that knee. The two libp2p defaults differ here: rust-libp2p's α=3 yields a ~0.6s median, while go-libp2p's α=10 yields ~0.3s, which is close to a 2x swing from a single parameter. The α=50 point is a single measurement separated by a wide gap from the rest of the curve and should be read as suggestive rather than load-bearing. Note that the graph does not show the cost side of the additional bandwidth and concurrent-connection pressure. This motivates the lower α starting values (3 or 5) for resource-constrained clients below in Step 3.
Starting values by network type
| Small + Stable | Small + Churning | Large + Stable | Large + Churning | |
|---|---|---|---|---|
k † |
5 | 10 | 15 | 20 |
| Record TTL † | 96 h | 48 h | 96 h | 48 h |
α |
3 | 5 | 5 | 10 |
| Refresh Period | 30 min | 15 min | 15 min | 10 min |
Rows marked † are network-wide constants and must take the same value on every server in the overlay. The per-publisher Record and Provider Publication Intervals follow from the TTL as roughly TTL/2 (48 h when TTL is 96 h, 24 h when TTL is 48 h).
Small networks are roughly 10^2 peers or fewer. Large networks are 10^4 peers or more. Medium-sized networks interpolate between adjacent columns. Stable refers to churn rates measured over hours or longer; churning refers to rates measured over minutes. Public deployments should additionally keep k at 20 if the threat model is adversarial. However, large k values may produce higher numbers of stale peer records in case of high network churn so the refresh rate should increased alongside it which again means higher networking overhead. The rightmost column approximates the public Amino DHT calibration.
Step 1: What are you using the DHT for?
The first question to settle is which DHT operations you actually need. Kademlia originally exposes two and the libp2p spec three protocol surfaces and they have very different operational profiles:
- Peer Discovery (required): You cannot run a DHT without peer discovery. After all, in every operating mode you need a way to find peers that participate in the network.
- Key-Value Store (optional): This allows you to
PUTandGETarbitrary value records into/from the DHT and this is what makes the DHT a distributed hash table as it conceptually functions as a decentralized map. - Content Routing (optional, unique to libp2p): Exposes
PUT/GETsemantics for special key-value pairs: provider records. In this operating mode the DHT functions as a content discovery index pointing to peers that hold specific data. This is what IPFS does.
A deployment can use any combination of 2. and 3. but cannot disable 1. The choice determines which subsystems of the implementation are active. A peer-discovery-only overlay leaves the entire record-management group of parameters at defaults because no records are exchanged, and Step 4 does not apply. A pure key-value deployment uses value records but not provider records. A content-routing deployment uses provider records but typically not value records.
If you are using the DHT for peer discovery only, you should additionally plan to disable both record subsystems explicitly. In Go this means setting DisableProviders and DisableValues, which requires operating under a custom protocol prefix because the Amino validator rejects these on /ipfs. Rust does not expose a single switch to disable both subsystems. The closest equivalent is to supply a RecordStore implementation that rejects writes, or to set inbound record filtering to FilterBoth and reject all records at the application layer.
Step 2: Characterise your deployment
The defaults assume a deployment that looks like the public Amino DHT: roughly a few thousand peers, moderate global latency, moderate churn, an adversarial threat model, and content-routing workload. Your deployment probably differs along one or more of the following dimensions. Before changing any parameter, characterise where you sit on each.
Network Topology: Do you plan to deploy stable, always-on, well-resourced server comprising the core of the network with clients interfacing with them or have all peers equal with varying resource constraints? Determines the judgement of the next item.
Topology stability: The rate at which peers enter and exit the network. Determines refresh cadence, replication frequency, and the safety margin between publication interval and record TTL.
Latency distribution: The RTT distribution across the peer population. A geographically concentrated deployment with sub-50 ms RTTs admits aggressive timeouts and lower query concurrency α. An intercontinental public network requires generous timeouts and higher α to converge in reasonable wall-clock time.
Adversarial threat model: Whether participants are trusted (single-operator cluster), known but not fully trusted (consortium), or potentially adversarial (public network). Drives the IP diversity filter, confirmation certainty β, and any application-supplied admission filters.
Resource constraints: Memory, CPU, and bandwidth available on each participating host. Constrains concurrency and refresh frequency.
Reachability profile: Whether nodes are able to accept inbound connections. Dictates operating mode. A node that cannot accept inbound connections must run as a client, otherwise it pollutes other nodes’ routing tables with phantom entries.
Your deployment may have multiple tiers of participating peers with different sets of configuration parameters. For example, it’s common for network operators to deploy a highly available core of well-resourced nodes and have lighter DHT clients as satellites around this core. The former and latter usage and deployment patterns warrant different configuration parameters. This is why we have defined different configuration profiles.
Step 3: Pick a profile
The five profiles below cover the deployment patterns most commonly observed in practice. Find the one(s) that most closely match(es) your case. Each profile opens with the assumptions it makes about its deployment context. If those assumptions match yours, the deviations it specifies are the right starting point. If no profile is a clean match, the closest match plus the factors from Step 2 should get you most of the way there. Parameters not discussed are left at their default values.
We want to emphasise that it is hard to predict or, when already deployed, know the network size and churn patterns. That’s where ProbeLab’s measurement expertise can help.
0. Network-wide constants and per-node knobs
Before picking a profile it is worth separating the parameters that must be agreed across the overlay from those that individual operators tune locally. The protocol depends on agreement for the first set. The second set is a local choice that does not affect other participants.
Network-wide constants. These must take the same value on every server in the overlay. They should be settled before any node is configured:
- Protocol Identifier defines the overlay. Simply put, this is a string identifying your particular DHT network. Mismatches mean disjoint networks that cannot exchange traffic.
- Bucket Size (
k) sets both the replication depth and the size for GET responses. Asymmetrickacross nodes breaks lookup termination heuristics and produces uneven record availability. - Value Record TTL and Provider Record TTL determine record persistence. Asymmetric TTLs make a record’s effective half-life depend on which storing peer holds the copy you queried.
- Provider and Value Store enablement determines which record RPCs are answered at all. Mixed enablement across servers produces non-deterministic record behaviour.
- IP Diversity Filter is technically a per-node admission policy, but the Sybil-resistance guarantee requires every server in the overlay to enforce it. Permissive peers are tiny holes in the defence.
Per-publisher, constrained by network-wide values. The publication intervals are per-publisher decisions, but their upper bound is set by the network-wide TTL with a safety margin (rule of thumb: TTL/2):
- Record Publication Interval for value records.
- Provider Publication Interval for provider records.
Per-node knobs. Different nodes can adopt different values for these without affecting the rest of the network. These are the levers individual operators tune for their own hardware, latency, and operational priorities:
- Query Parallelism (
α), Query Resiliency (β), Query Timeout - Refresh Period, Latency Tolerance, Auto Refresh
- Operating Mode, Bucket Insertion Strategy, Pending Entry Timeout
- Admission Check Concurrency, Query Peer Filter, Routing Table Filter
- Disjoint Query Paths, Lookup Caching, Inbound Record Filtering, Record Replication Interval
The profile recommendations below cover both kinds of parameters. When a profile suggests a value for a network-wide constant, treat it as a recommendation for the network’s choice rather than a value an individual node should deviate to in isolation.
1. Public Server Node
We assume a node operated on stable infrastructure with a permanent public IP and sufficient bandwidth to absorb sustained inbound query traffic. The node operates in server mode. No assumption is made about which protocol surface is in use; this profile covers public deployments across peer discovery, key-value storage, and content-routing use cases.
On the public Amino DHT, the go-libp2p defaults are calibrated for this profile and no parameter changes are required. For public deployments under custom protocol prefixes the defaults remain a reasonable starting point, and deviation should be motivated by the dimensions outlined in Step 2.
The operating mode decision is worth making explicitly. ModeAuto defers server-mode entry until libp2p detects public reachability at runtime, which can take tens of seconds at startup. ModeAutoServer enters server mode immediately and only retreats to client mode if reachability is subsequently disproven. The latter is preferable when reachability is expected based on deployment topology rather than discovered at runtime.
The defaults target a peer population in the 10^3 to 10^4 range and were calibrated against the Amino DHT’s specific latency distribution. Smaller networks of a few hundred peers or fewer converge quickly under iterative lookups and tolerate lower Query Parallelism α in the range of 3 to 5 alongside a longer Refresh Period. Larger networks of a few thousand peers benefit from a tighter refresh period toward 5 minutes to keep the routing table aligned with topology drift. Geographically concentrated deployments with sub-50 ms median RTTs additionally justify a shorter Query Timeout and tighter Latency Tolerance, while intercontinental deployments should keep defaults or tend toward the upper end of those ranges.
Bucket size should remain at 20 for any public deployment regardless of size. On the /ipfs prefix this is enforced by the config validator in go-libp2p. On custom public prefixes the same logic applies, since the adversarial threat model rewards the replication depth and limits eclipse-attack feasibility.
Churn rate sets the cost-availability trade-off for both the routing table and the record subsystem. High-churn networks should keep refresh and replication intervals at or below their defaults and maintain a generous safety margin between publication interval and record TTL. Low-churn public networks can extend the Refresh Period to 30 minutes or more.
The security parameters depend on the threat model. Public networks rely on the IP Diversity Filter for Sybil resistance and the defaults should be preserved. Consortium deployments with potentially Byzantine participants benefit from enabling Disjoint Query Paths in Rust.
If the provide subsystem is enabled, the Provider Publication Interval is the parameter most directly tied to operational cost. The appropriate value depends on network churn and on k. Higher churn shortens the safe interval because records die faster as their storing peers leave. Higher k extends the safe interval because more replicas survive any given turnover event. The 22-hour Amino default assumes k = 20 and the Amino-observed churn rate; networks with lower churn or higher k can extend the interval, and networks with higher churn or lower k should tighten it. In all cases the interval should sit at roughly TTL/2 to preserve the safety margin against record expiry.
We recommend to always enable Reprovide Sweep and if necessary to have fast record availability to optionally also enable Optimistic Provide. We recommend not using Optimistic Provide for bulk content publication, but only for cases where fast availability is required.
2. Resource-Constrained Client
We assume a node that operates under tight limits on at least one of memory, CPU, or bandwidth, and uses the DHT infrequently rather than maintaining continuous involvement.
Operating mode must be set to client. Running in any server-capable mode from a non-reachable host inserts phantom entries into other nodes’ routing tables and degrades routing quality for the rest of the network. Setting this explicitly with ModeClient avoids runtime detection delays.
The most consequential parameter adjustments concern background activity. The α default of 10 generates concurrent open streams that exceed what most constrained hardware can sustain comfortably; values between 3 and 5 retain acceptable lookup latency while bounding peak connection pressure. The refresh period should be extended to 30 to 60 minutes, or auto-refresh disabled entirely if the application explicitly triggers bootstrap before each session of DHT activity. The Admission Check Concurrency, which gates parallel reachability probes at routing table insertion time, should be reduced to between 8 and 16 for low-memory environments. This slows startup convergence but has no steady-state effect once the routing table is populated.
Bucket size can be reduced from 20 to between 10 and 15 if routing table memory is a hard constraint. This requires a custom protocol prefix because the Amino validator rejects k changes on /ipfs. The trade-off is modestly reduced lookup quality in exchange for roughly halved routing table memory.
Clients that do not announce content benefit from disabling the provider subsystem entirely. This requires operating under a custom protocol prefix, since the Amino validator rejects DisableProviders on /ipfs. For Rust-based deployments the equivalent posture is achieved by leaving the provider publication interval unset and not invoking the provide API.
3. Peer Discovery Overlay
We assume a public or semi-public network that uses the DHT exclusively for peer discovery. Lookups are issued as FIND_NODE operations or as part of routing table maintenance, and neither value records, nor provider records are exchanged. Examples include Polkadot’s validator and parachain peer discovery and various libp2p-based blockchain networks. The deployment typically operates at moderate size, in the thousands to tens of thousands of nodes, and exhibits lower churn than the public Amino DHT, but higher than a controlled datacenter cluster.
A custom protocol prefix is mandatory. Without it, nodes join the public Amino DHT and inherit Amino-specific validator constraints that are inappropriate for peer-discovery-only use.
Both record subsystems should be disabled. In Go, set DisableProviders and DisableValues. This removes the corresponding RPC handlers and prevents the node from being asked to store records that the application has no interest in. Rust does not expose a single switch to disable both subsystems. The closest equivalent is to supply a RecordStore implementation that rejects writes, or to set Inbound Record Filtering to FilterBoth and reject all records at the application layer. The RPC handlers remain active in that case but the node stores nothing.
The α default of 10 was tuned for Amino content lookups. For a peer-discovery workload with different lookup volume and latency distribution, the optimum may be lower. Networks with modest peer-set size and low RTT often operate well at α between 3 and 5. Bucket size can also be reduced from the default of 20, since k does not drive record replication in a peer-discovery deployment and only governs routing table coverage. Networks in the thousands to tens of thousands of nodes operate adequately at k between 15 and 20, trading a small amount of routing table redundancy for reduced memory and per-lookup bandwidth. The IP Diversity Filter should remain enabled for any public-facing deployment, since Sybil pressure is independent of whether the DHT serves records or only peer discovery. Operating mode follows the same logic as in the public server profile.
Step 4 (further down) does not apply to this profile and can be skipped entirely.
4. Private or Datacenter Cluster
We assume a closed network operated by a single entity or a small consortium. Infrastructure-level reachability is known a priori, peer churn is low, and isolation from the public Amino DHT is enforced through a custom protocol prefix. Honest nodes are likely to share IP address blocks because they share hosting infrastructure.
The protocol prefix change is mandatory. Without it, nodes join the public Amino DHT and the cluster ceases to be private. Operating mode should be set to server unconditionally, since reachability auto-detection adds startup latency without operational benefit in a controlled environment.
The most consequential routing change is the IP Diversity Filter. The Amino defaults limit routing table admission to three peers per /16 IPv4 block globally and two per /16 per bucket. In a datacenter where honest nodes naturally share /24 blocks or wider, these limits reject the majority of legitimate candidates and leave the routing table chronically under-populated. The filter should be removed or replaced with a permissive equivalent.
A custom prefix also lifts the Amino validator’s constraint on bucket size. On a stable, low-churn topology, reducing k to 10 cuts per-provide bandwidth proportionally without meaningfully affecting record availability. Disabling whichever of provider or value records the application does not use removes the corresponding RPC handlers and simplifies the operational surface.
For deployments where some cluster members may be Byzantine, the Rust implementation’s Disjoint Query Paths option provides resistance to routing manipulation by sending lookups along α non-overlapping paths. The latency cost is modest in a low-RTT environment and acceptable in exchange for the security guarantee. The refresh period can be extended toward 30 minutes or longer, since a stable peer set requires less frequent topology reconciliation.
5. High-Throughput Provider
We assume a node serving a large content corpus to the public Amino DHT in the role of a pinning service, gateway, or content indexer. The workload is dominated by outbound provider announcements and the corresponding inbound GET lookups rather than general-purpose record retrieval. Public reachability and a generous bandwidth budget are preconditions.
Operating mode must be server. Bucket size remains at the Amino-locked 20: the public threat model rewards the replication depth, and the validator would reject a change in any case. The refresh period should be tightened to 5 minutes to maintain a closely-tracked routing table, since iterative lookups dominate the workload and benefit directly from routing table accuracy.
Reprovide Sweep is effectively mandatory at this scale. Above approximately 10⁴ CIDs the per-CID reprovide path is no longer viable regardless of how the publication interval is set, and the sweep is the only mechanism that brings the operation count back into a tractable range. It should be preferred over the older Accelerated DHT Client, whose periodic full-network crawl produces bursty CPU and bandwidth spikes that complicate capacity planning.
Optimistic Provide is worth enabling specifically when fast first-announcement of newly added CIDs matters, for example when root CIDs need to become discoverable promptly after ingest. The optimisation only affects the latency of the initial provide; subsequent reprovides on the regular cycle are unaffected. For workloads where ingest latency is not user-visible, the benefit is not evident.
Query parallelism becomes relevant only in combination with Optimistic Provide, where a higher α allows the optimistic candidate set to converge more aggressively. The default of 10 is already fast on a global network, and increasing it to 15 yields only modest additional gains. For deployments without Optimistic Provide enabled, the default α is sufficient.
The provider publication interval is the parameter most directly tied to sustained operational cost. The 22-hour default tracks the TTL/2 rule for the Amino calibration and is appropriate for steady operation. Reducing it requires a specific reason such as significantly higher than Amino-observed churn.
Step 4: Provide optimisations (content routing only)
This step applies only if your protocol surface (from Step 1) includes content routing via provider records. Skip otherwise.
A provide operation requires significantly more wall-clock time and bandwidth than a typical lookup because it must reach the k closest peers to the target CID rather than terminate early on the first satisfactory response set. At any meaningful content scale this cost dominates the operational profile of a DHT node. Three optimisations address different aspects of it. Reprovide Sweep is the primary scaling mechanism and is effectively mandatory above a moderate corpus size. Optimistic Provide is a situational complement that addresses first-announcement latency specifically. The Accelerated DHT Client is an older alternative to the sweep that remains in production but is no longer the recommended starting point.
Reprovide Sweep
A node hosting a large content corpus must reprovide every CID independently of the publication cycle. With one full iterative lookup per CID, a corpus of 10 million records on a 22-hour cycle generates approximately 125 sustained lookups per second. The bandwidth and CPU cost scales linearly with corpus size and quickly exceeds the capacity of standard server hardware.
The Reprovide Sweep batches reprovide operations by keyspace region rather than by CID. The local corpus is sorted by XOR distance to a sweep cursor that traverses the keyspace systematically. For each region, the node performs a single lookup to identify the responsible peers and then dispatches ADD_PROVIDER RPCs for all locally-held CIDs that fall within that region as a batch to those peers. The total lookup count drops from O(N) to approximately O(N/k). Design rationale and measured performance are documented in the IP Shipyard write-up.
The sweep is effectively required for any node hosting more than approximately 10⁴ CIDs on the public DHT. Below that scale the standard per-CID reprovide path remains viable. Above it, the optimisation transitions from helpful to operationally necessary. It is the primary scaling mechanism for content-routing deployments and supersedes the Accelerated DHT Client for new workloads as the following graph indicates:
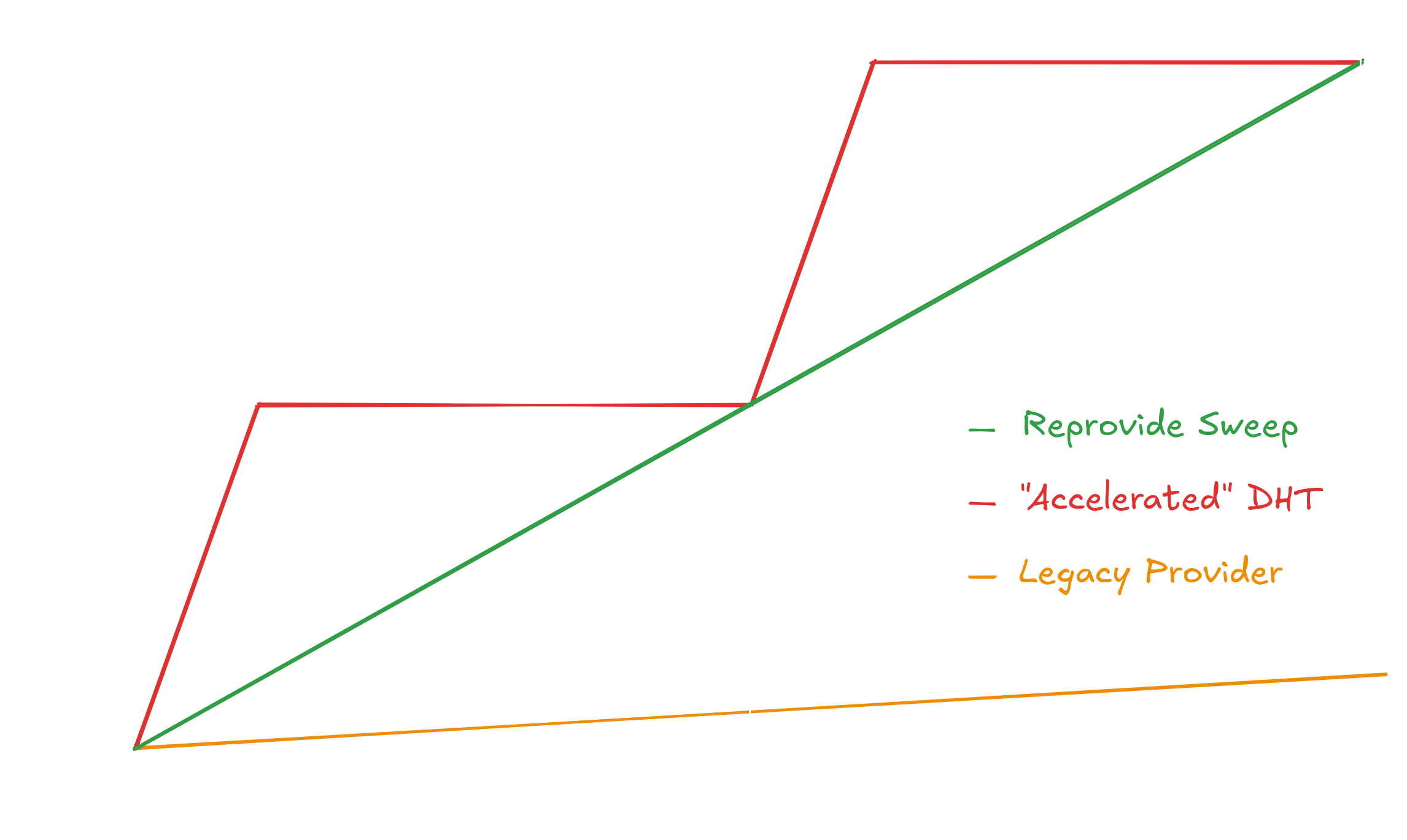
Reprovide sweep has a steady reprovide rate as the legacy provider but a much steeper slope. Compare this with the accelerated DHT where the bursty resource profile is visible. More on that in the following section.
Accelerated DHT Client
The Accelerated DHT Client (referred to as fullrt in the go-libp2p codebase) maintains a continuously refreshed local map of the entire DHT routing space, populated by an ongoing crawl. Lookups become local computation against this map rather than network operations. ADD_PROVIDER and GET_PROVIDERS still require RPCs to the responsible peers, but the cost of identifying those peers drops to zero.
The accelerated client addresses the same scaling problem as Reprovide Sweep but with a different trade-off. The local routing map requires several gigabytes of resident memory, and the periodic full-network crawl produces bursty CPU and bandwidth spikes that complicate capacity planning. Reprovide Sweep achieves comparable per-operation throughput without either cost.
The Accelerated DHT Client remains in production at several large operators and continues to work as designed, but it is no longer the recommended starting point for new deployments. Operators migrating to Reprovide Sweep can expect smoother resource curves at similar steady-state throughput.
Optimistic Provide
The final hops of an iterative provide lookup are statistically the most expensive. As the candidate set converges on the k closest peers, most contacted peers can no longer return a closer neighbour, yet the lookup engine waits for confirmation before terminating. On the global Amino DHT this tail accounts for the majority of provide latency.
Optimistic Provide replaces the tail with a probabilistic shortcut. The node maintains a running estimate of network size using the keyspace density observed during ongoing lookups. When the expected distance of the current candidate set falls below a threshold derived from this estimate, the node assumes it has found peers close enough to the target and dispatches ADD_PROVIDER RPCs to the best current candidates without completing the full lookup. A configurable number of additional RPCs continue in the background after the operation has returned to the caller. Empirical characterisation by ProbeLab is available in the Optimistic Provide write-up. The following graph shows the performance improvement as the technique became the default in Kubo 0.39.0.
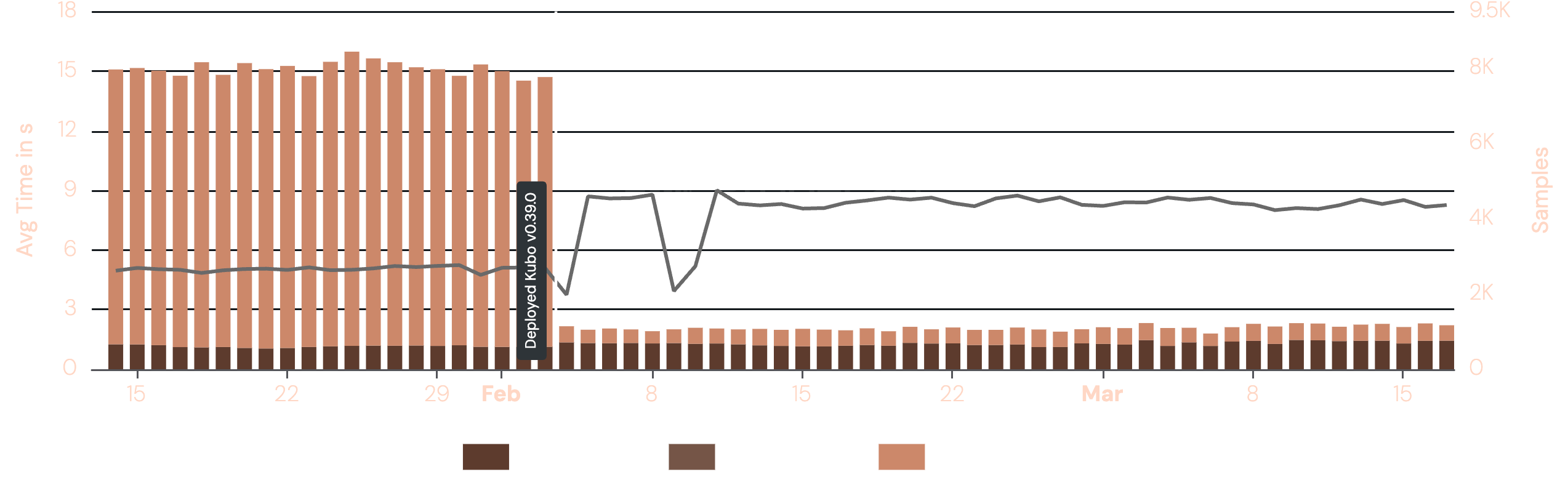
Optimistic Provide is a situational tool. It is appropriate specifically when fast first-announcement latency for newly added CIDs is operationally visible, for example when root CIDs need to become discoverable promptly after ingest. The optimisation does not help with periodic reprovide cycles, which already run in batch under the Reprovide sweep. For workloads where ingest latency is not user-visible, the benefit is not evident.
Choosing between the three
Reprovide Sweep is the primary mechanism for content-routing at scale and should be enabled for any deployment whose CID corpus exceeds approximately 10⁴. Optimistic Provide is complementary and should be layered on top of the sweep when first-announcement latency matters, for instance when newly ingested content needs to become discoverable within seconds. The Accelerated DHT Client is the older alternative to the sweep and is not typically combined with it. New deployments should prefer the sweep, and existing accelerated-client deployments should plan to migrate.
Where to go from here
As might have been clear by this point, DHTs are complex structures with lots of knobs to tune. We believe that this report is a good guide to cover more than the basics for network engineers and node operators. But of course, there is more. Below are two studies we did in the past for the IPFS Amino DHT, which we recommend for those that want to make sure their setup is as efficient as can be. We also discuss some network metrics worth keeping an eye on. Last but not least, we have not talked about DHT security. We give hints on what to monitor in order to make sure the network does not run the risk of eclipse attacks.
Performance Efficiency Studies
Two of the most important functions of a DHT network are to be able to: i) route efficiently, ii) keep records live (and therefore content discoverable). The following two studies, carried out for the IPFS network by the ProbeLab team in 2022, are targeting those two DHT functions.
-
IPFS Amino DHT Routing Table Health: the study’s goal was to see how effective and efficient is routing in IPFS’s Amino DHT network. In particular the study focused on the following items:
- the percentage of stale entries in the routing tables
- the peer distribution in Kademila k-buckets
- the number of missing peers in the k-buckets
- whether IPFS nodes have their 20 closest peers in their routing tables
Our study showed that the IPFS Amino DHT routing table is in a healthy condition from every examined angle.
-
IPFS Amino DHT Provider Record Liveness: one of the most important tasks of a DHT server node is to store and provide records (e.g., information for content location, or peer addresses). Those records expire after some time and need to be republished in order to make sure that information kept in the network is fresh and up-to-date.
This study is important to carry out for every DHT network, because absence of those records from the network (either because they expire and not renewed, or because nodes that store those records leave the network) means that the corresponding information that the record holds is not available in the network.
Our findings from measuring the liveness of provider records in the IPFS Amino DHT were encouraging to the point that we have suggested and landed an increase in the record republish interval to reduce traffic overhead of republication.
Important Metrics
Provider record liveness makes for a good leeway into two important metrics: node churn and stability of PeerIDs.
Peer Churn
This metric observes how frequently nodes depart and rejoin the network. It is a measure of stability and, as discussed earlier in this report, affects several other parameters. High peer churn means that nodes are not stable and while they might be reachable at one point, they have likely gone offline the next time another peer tries to reach them.
For the IPFS Amino DHT peer churn is shown in this plot: https://probelab.io/ipfs/security/#chart-sessions-churn-cdf. The plot shows that peer churn in the Amino DHT is at acceptable levels: 6% of nodes have left the network within 12 hours after they have joined. Although this might sound too high for some use-cases, for the particular case of content distribution, which is the focus of the IPFS network, we argue that it is reasonable. And it has clearly improved lately, thanks to the stability of kubo , compared to our 2022 study.
Rotating PeerIDs
A peer that shows up with PeerID A at point t1 and with PeerID B at point t2 is effectively cancelling all of the state that it has acquired and publicised through its previous PeerID. For instance, if a provider record is made public from a peer with PeerID A, then other nodes will search for that PeerID when they want to retrieve the same record. If the peer has switched to PeerID B by that point, then a few things get messed up. Rotating PeerIDs are a form of peer churn and therefore, if observed frequently contribute to network instability.
It is important to keep an eye at how often and how many peers rotate their PeerIDs. If these go beyond a threshold, then the network runs the risk of becoming unstable.
Security Considerations
Peer-to-peer networks have traditionally been threatened by Sybil and Eclipse attacks, due to their open and permissionless nature (i.e., the fact that in most cases anyone can spin up a node and participate in the network). Although there are many incarnations of Sybil and Eclipse attacks, the most well-known and widespread one is that of a malicious actor spinning up many Sybils that surround one or more peers and limit (or completely eclipse) the victim’s capability of communicating with other nodes in the network.
If you anticipate that your network will only have a few dozen or a few hundred peers, be aware that mounting a Sybil attack is cheap at that scale, leaving your network considerably more exposed to one.
An elegant way of identifying whether an eclipse attack is underway is to monitor the key-space density, which ProbeLab does for the IPFS Amino DHT, among other networks:
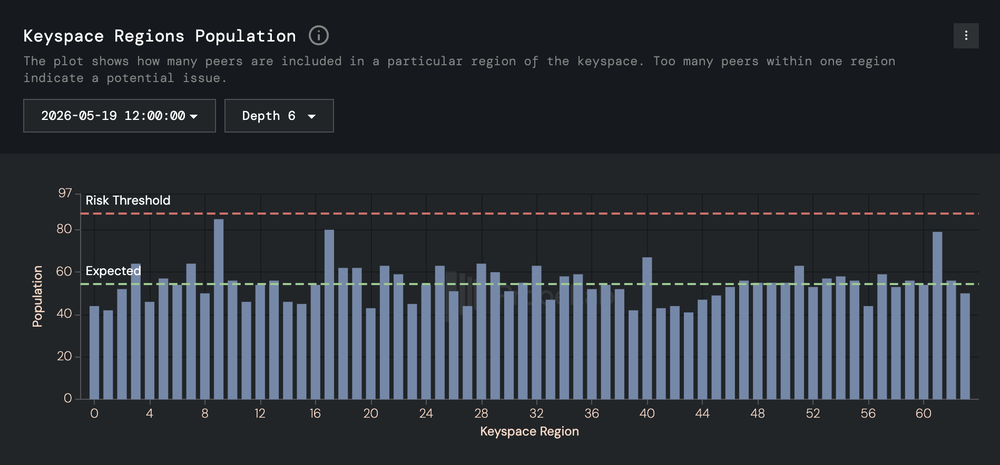
Although monitoring itself is not mitigating the potential attack in any way, it is clearly an important metric to have under observation. Mitigation strategies go beyond the scope of this report, but one important configuration parameter is the “IP diversity filter”. According to this filter, a node is limiting the number of routing table entries it accepts from a particular IP range. The assumption is that a malicious actor will attempt to spin up all of its Sybil nodes from one location for operational efficiency and cost effectiveness reasons.
Closing Remarks
Admittedly, not all of what has been mentioned here is straightforward and most of it needs some specialised tooling and skillset. ProbeLab’s tools are open-source and we encourage engineers to play around, use them, deploy them and get deep insights into their networks. ProbeLab is always happy to help make sure that tools are correctly configured and deployed and the right results are obtained. Reach out if you need help.
Related Posts

Performance Audit of libp2p’s AutoNAT
Is your libp2p node publicly reachable? A performance audit and node operator guide on libp2p's AutoNAT.

libp2p Kademlia DHT Configuration Parameters
The definitive guide to every libp2p Kademlia DHT configuration parameter; what each one does, why defaults exist, and when to override them.

Optimistic Provide: How We Made IPFS Content Publishing 10x Faster
How a statistical approach cut IPFS content publishing times by over one order of magnitude.