A Toolbox for libp2p Network Monitoring
Dennis Trautwein · Mikel Cortes
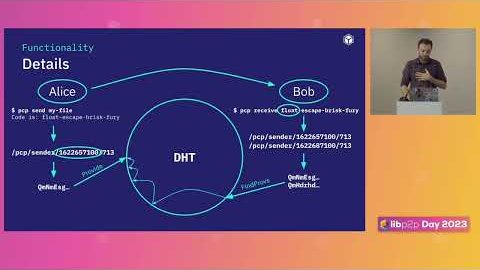
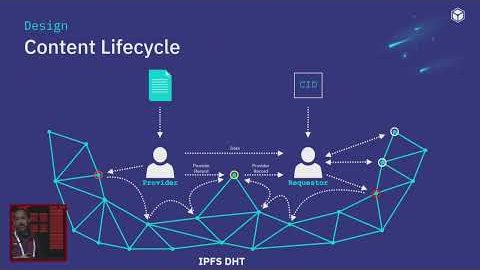
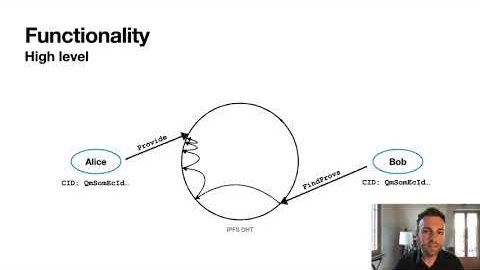
Dennis Trautwein and Mikel introduce ProbeLab's mission of rigorous P2P protocol measurement and walk through the full suite of libp2p monitoring tools they have built, including Nebula and Ants for network topology, Bemo for uptime and IPFS website monitoring, Hermes for protocol-level tracing, Ukla for bandwidth measurements, Parsec for DHT lookup monitoring, and newer tools like Akai for data availability. Mikel then dives into Hermes, a lightweight gossipsub tracer, and presents findings on the GossipSub 1.2 IDONTWANT control message: while it does reduce duplicates, around 60% of IWANT requests arrive within 10 milliseconds of the actual message and roughly half of duplicates still arrive within 500ms of an IDONTWANT, partly because GossipSub uses a single stream per peer that cannot cancel an in-flight transfer. The talk closes with plans for Hermes++, a lighter version that can scale horizontally without eclipsing peers, and the goal of turning probelab.io into the reference point for P2P metrics across multiple networks.