NAT Hole Punching Campaign Update
Dennis Trautwein
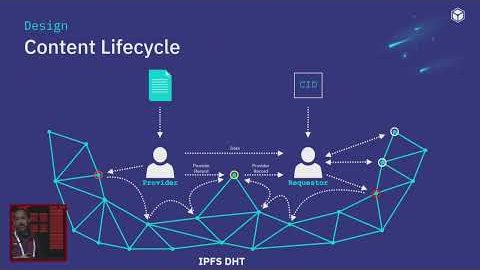
A mid-campaign update from PL Demo Day 2022 on ProbeLab's distributed NAT hole punching measurement, in which volunteers run a "punchr" client that attempts libp2p hole punches against random peers across the public IPFS network. By mid-December the campaign had around 80–90 active clients per day across all continents except Africa, contributing roughly 150,000 hole-punch results daily and over three million in total. Dennis shows that the remote peers being punched span a geographically diverse set of countries, which compensates for client-side location skew, and reports a preliminary success rate fluctuating between 60–70% — slightly below earlier controlled-network measurements, as expected for a heterogeneous deployment. The talk closes with a call for additional participants and points to both the menu-bar macOS client and command-line tooling for joining the campaign.